
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion. . Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale..
What You Need To Know About Meta S Llama 2 Model Deepgram
Chat with Llama 2 70B Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your. Experience the power of Llama 2 the second-generation Large Language Model by Meta Choose from three model sizes pre-trained on 2 trillion tokens and fine-tuned with over a million human. Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly available instruction datasets and over 1 million human annotations. With more than 100 foundation models available to developers you can deploy AI models with a few clicks as well as running fine-tuning tasks in Notebook in Google Colab. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration..
This notebook provides a sample workflow for fine-tuning the Llama2 7B parameter base model for extractive Question. Merge the adapter back to the pretrained model Update the adapter path in merge_peft_adapterspy and run the script to merge peft adapters back to. This jupyter notebook steps you through how to finetune a Llama 2 model on the text summarization task using the. CUDA_VISIBLE_DEVICES0 python srctrain_bashpy --stage rm --model_name_or_path path_to_llama_model --do_train -. N Merge the adapter back to the pretrained model n Update the adapter path in merge_peft_adapterspy and run the script to merge peft adapters back..

Llama 2 Model Sizes 7b 13b 70b
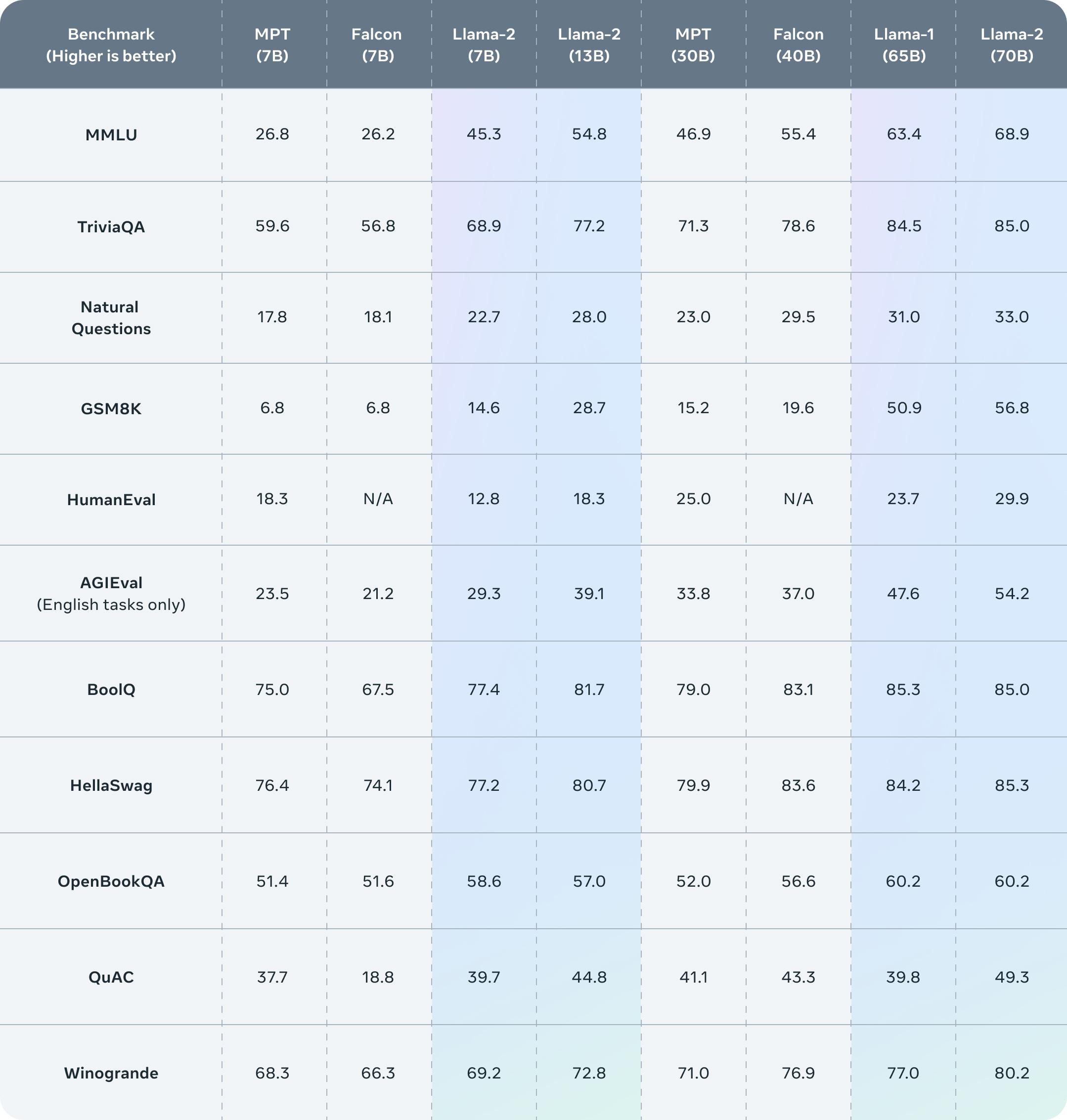
Llama-2-Chat which is optimized for dialogue has shown similar performance to popular closed-source models like ChatGPT and PaLM. In this notebook and tutorial we will fine-tune Metas Llama 2 7B Watch the accompanying video walk-through but for Mistral. -- LLaMA 20 was released last week setting the benchmark for the best open source OS language model. Open Foundation and Fine-Tuned Chat Models In this work we develop and release Llama 2 a collection of pretrained and fine-tuned. Fine-tuning is a process of training an LLM on a specific dataset to improve its performance on a particular task In this case we will fine-tune a..




Comments